完整架构 · 从你的屏幕,到 AI 的眼睛
① 客户端 · 你的电脑(采集端)
采集活跃窗口 · 关键帧截图 · 时间
隐私过滤黑名单 / 暂停
Outbox 队列幂等 · 断点续传
托盘 · 多路径选路
↓
② 链路 · 自动选最优的一条
在家 → 局域网直连 192.168.*.*就近、最快
在外 → 域名 → VPS(nginx) → FRP 隧道无公网 IP,绕一圈;延迟不重要、带宽重要
↓
③ 服务端 · 家里小主机(常驻 · RTX 3080)· 数据不出门
API(FastAPI)
存储SQLite + 本地文件
分析 WorkerVLM 看图 → 描述 + 分类
本地模型VLM 35B · Embedding
三路检索关键词 FTS5 · 以图搜图 pHash · 语义向量
分析队列状态机 · 崩了自愈
看板生成器定时出 AI 报告
↓
④ 谁在用它
你 → Web(域名 · 登录)时间轴 · 看板 · 搜索
AI → Agent 问答 · MCP 导出OpenClaw / Claude Code 主动来读
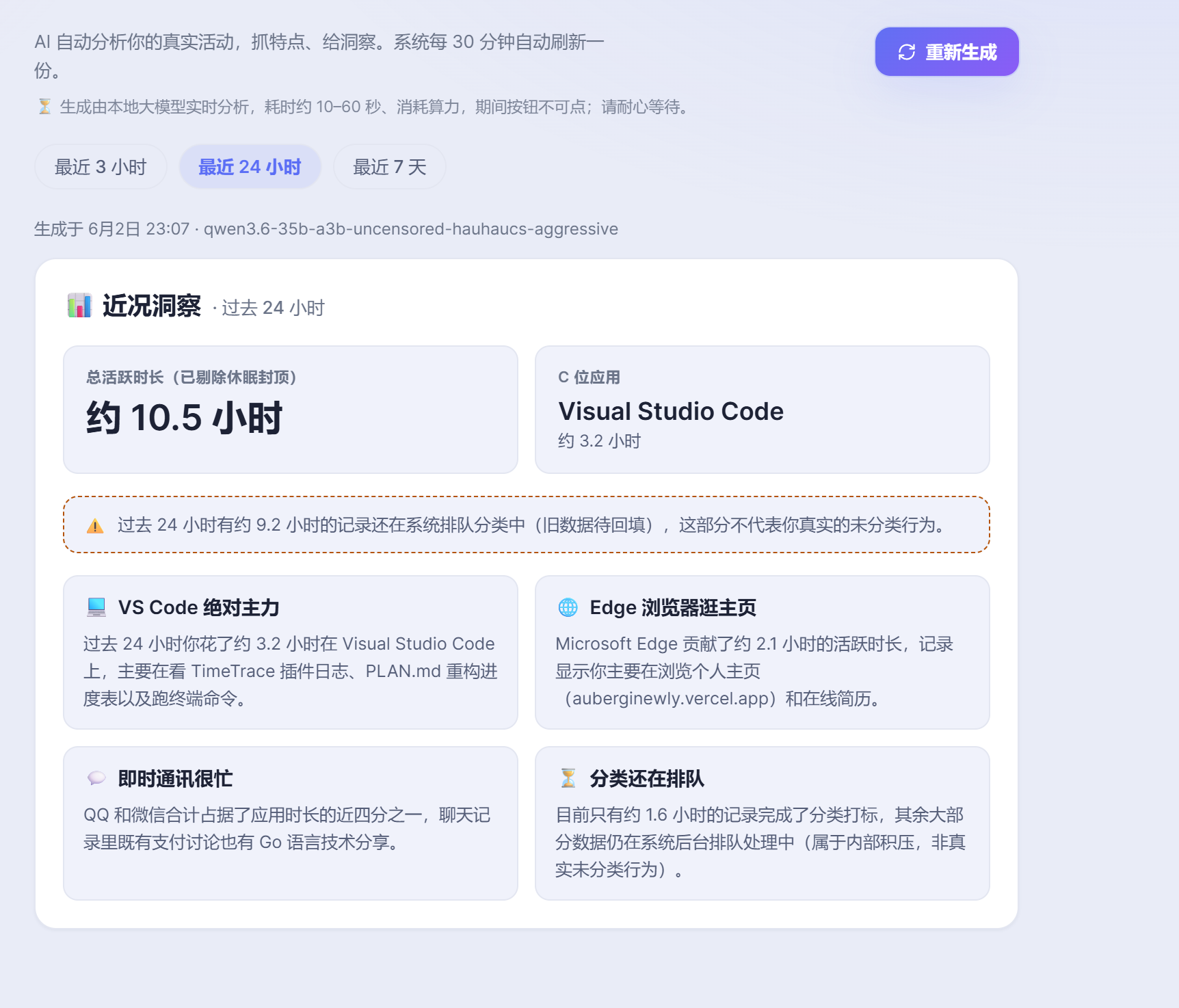
架构跑完,你每天看到的看板就长这样 👆
两个 AI 入口 · 定位不一样
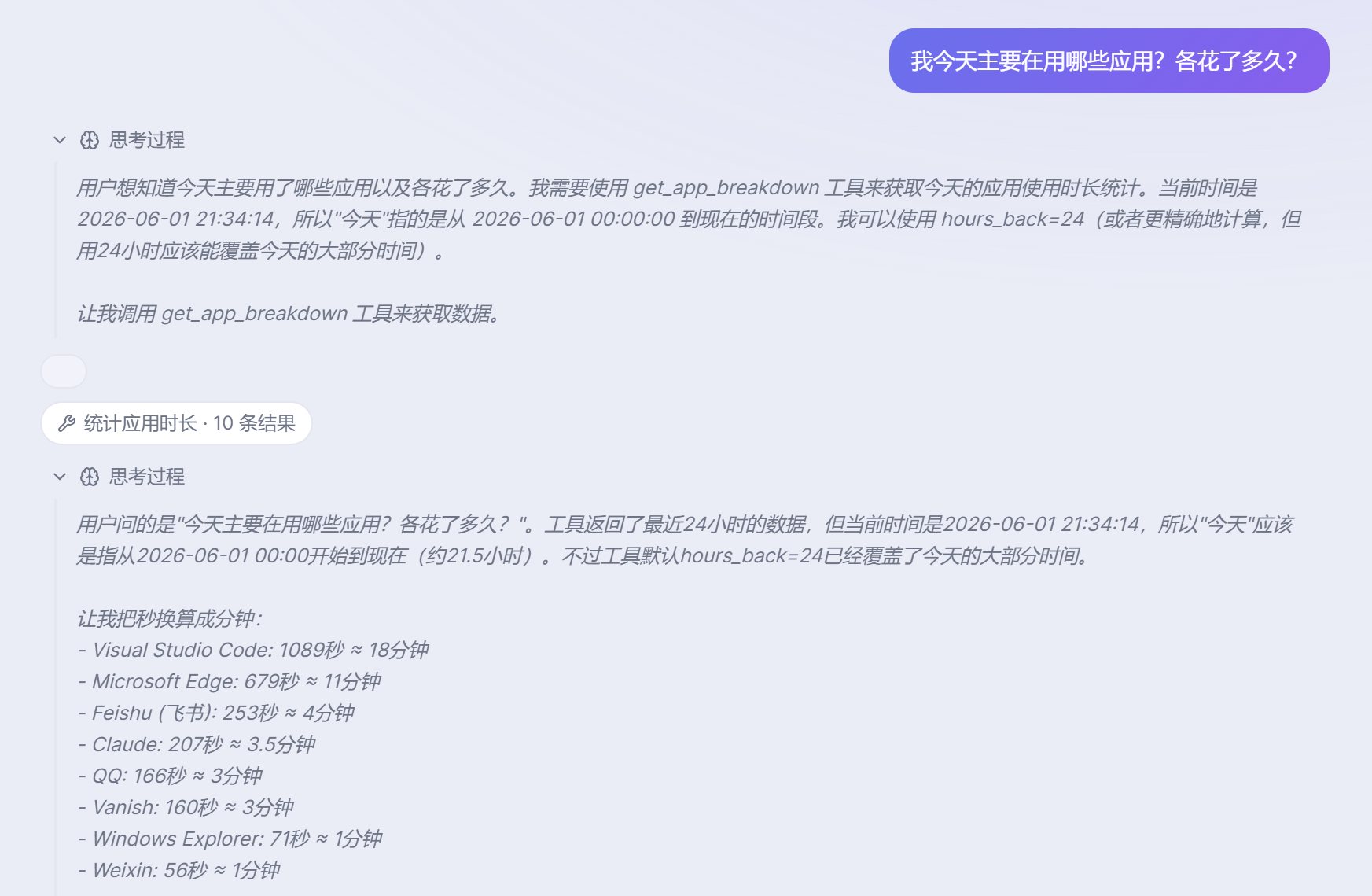

💬 Agent · 你问,它答
用大白话问,它自己调工具去翻你的活动记忆,再回答你。
例:今天主要用了哪些应用?各花了多久?
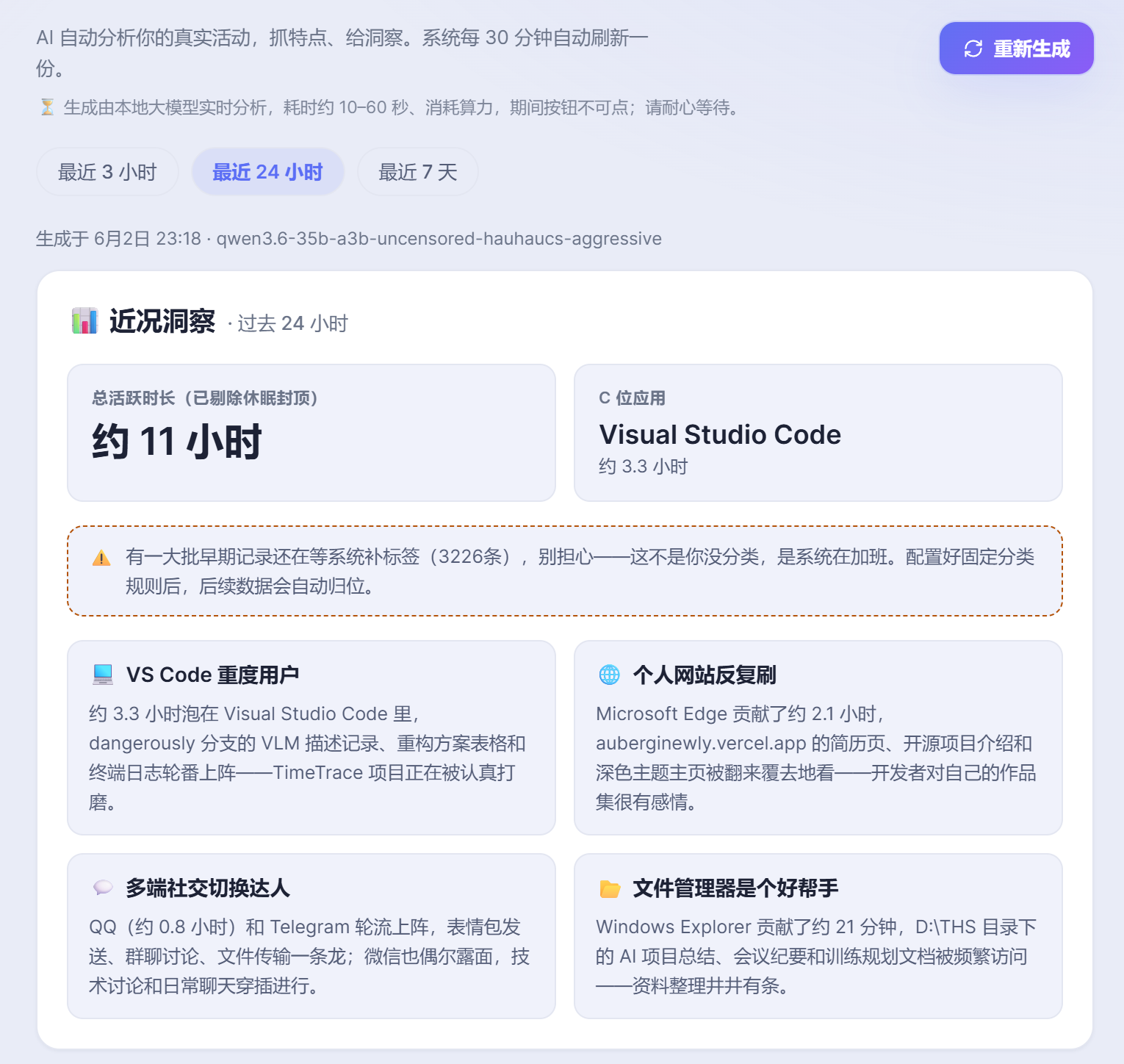
📊 看板 · 它主动给你看
每 30 分钟自动出一份「最近在干嘛」的洞察,像网易云年报。你打开就看,不用开口问。
很会抓特点
摸鱼大师…?
摸鱼大师…?
全程 AI 实时生成
调工具 → 落笔写报告
调工具 → 落笔写报告
可能可以问他什么
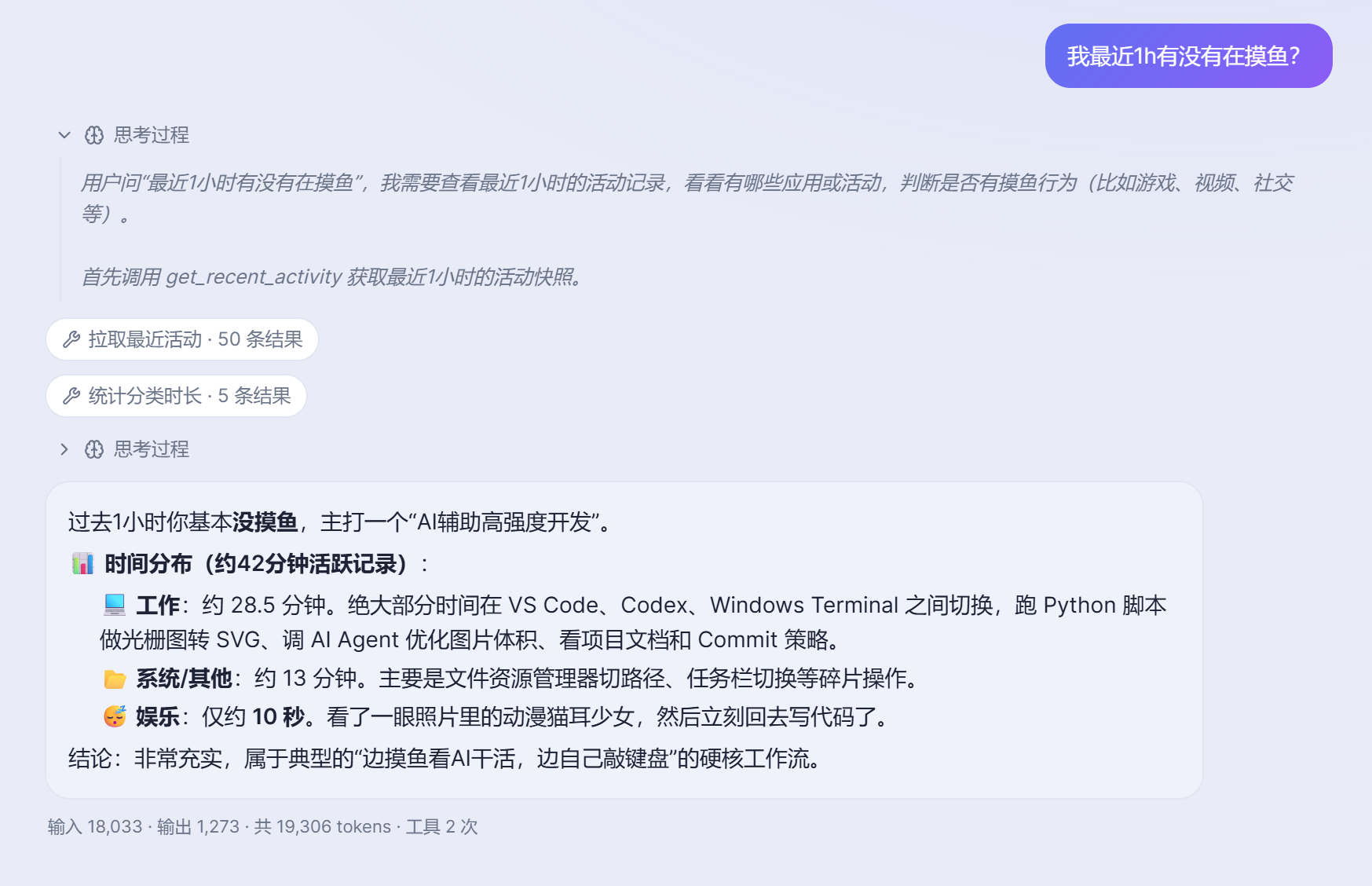

从随口一问,到有点刁钻的,它都能接。
「我最近 1 小时有没有在摸鱼?」
「昨天上班 10–21 点,有没有跟人聊天?什么软件、跟谁?」
这周工作多久?
写代码 vs 开会?
最近 3 小时在干嘛?
用得最多的 app?
一点小美化?
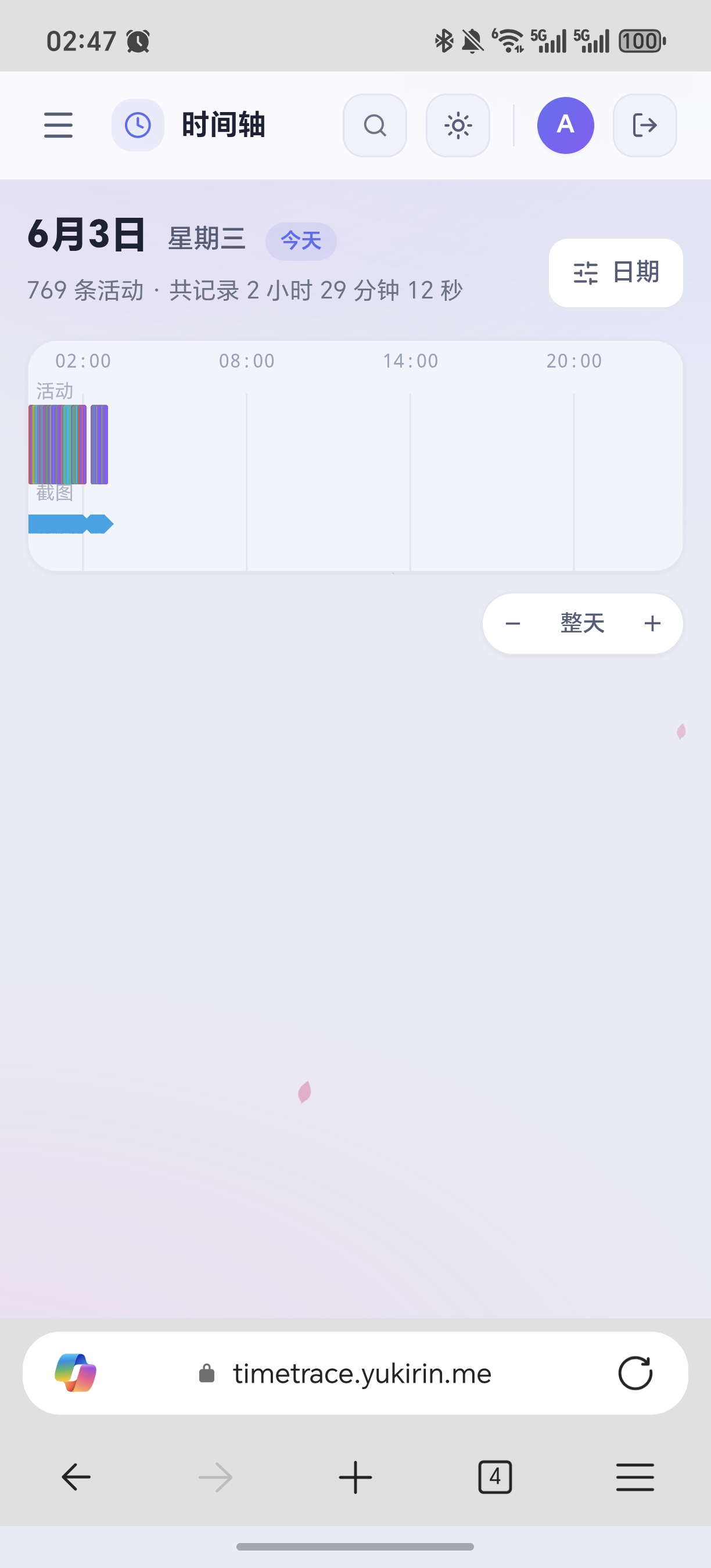
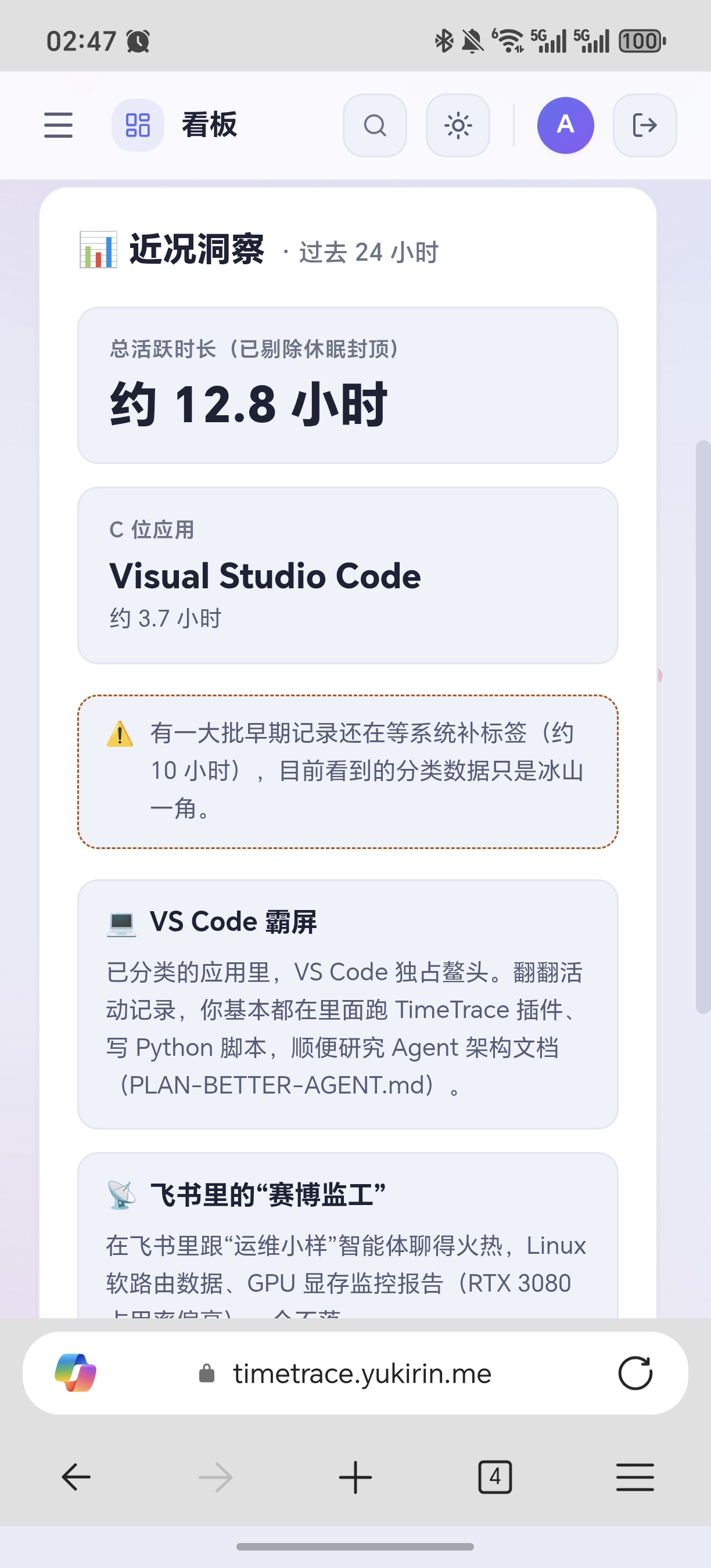
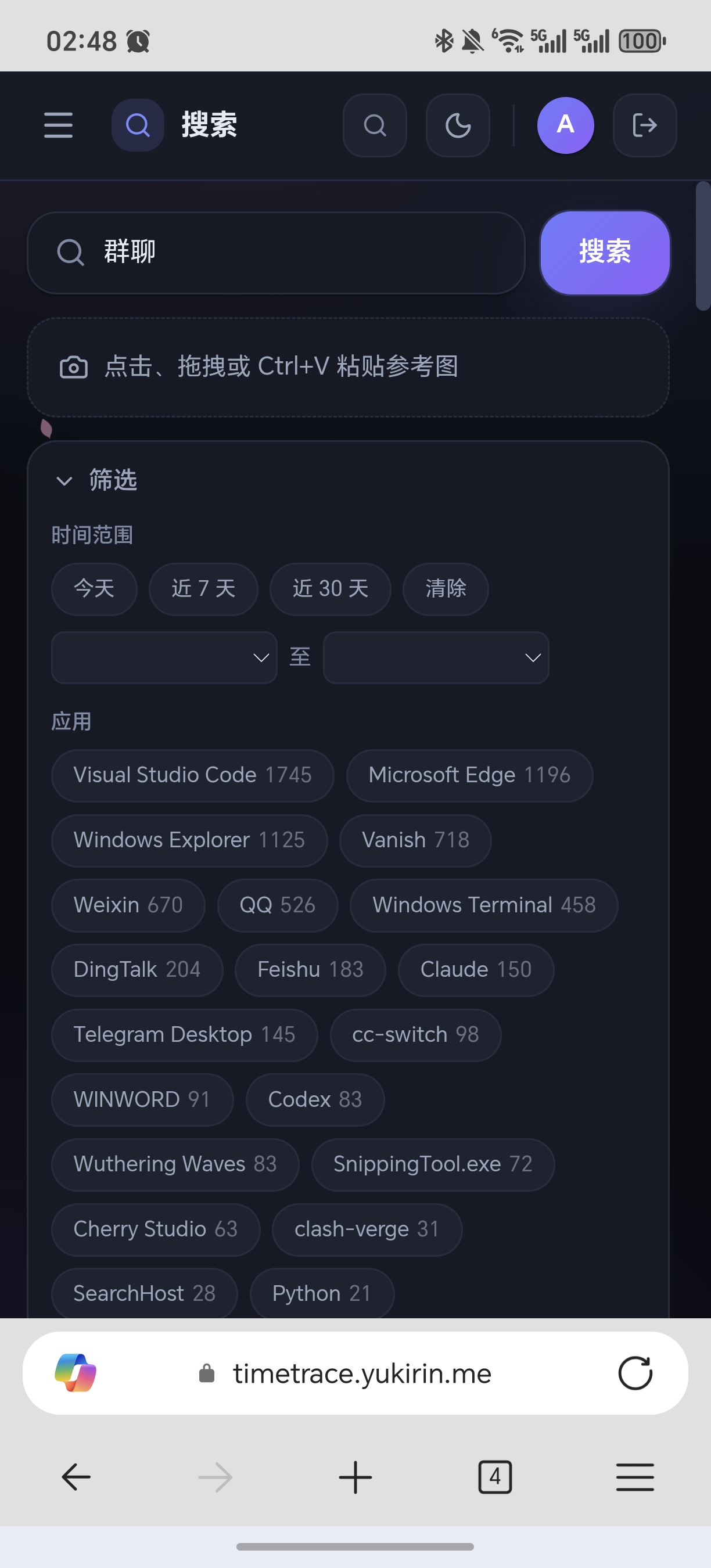
手机(竖屏)也能看,白天黑夜双主题也有。
☀️ 白天模式
🌙 夜间模式